

Thanks for the subs! For those of us who don't subscribe to filejoker, are the zip files available on other sites such as https://mega.nz , which don't requre a subscription? ThanksHere's another update of my "all subtitles ever posted to this thread" collection.
Since then, there have been 722 subtitles posted.
View attachment 3168627
Version 4 is now up to 33,066 subtitles. All files have been renamed, language IDs added, checked for issues, and sorted alphabetically by ID. Enjoy!
FileJoker:
Rapidgator:
Quick plug: JavLuv 1.1.22 was used to sort these subtitles, and can also match your movie collection to available subtitles as well. It's completely free and open source, and I support it here in these forums.
Post your JAV subtitle files here - JAV Subtitle Repository (JSP)★NOT A SUB REQUEST THREAD★
- Thread starter Eastboyza
- Start date
-
Akiba-Online is sponsored by FileJoker.
FileJoker is a required filehost for all new posts and content replies in the Direct Downloads subforums.
Failure to include FileJoker links for Direct Download posts will result in deletion of your posts or worse.
For more information see this thread.

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Filejoker doesn't require a subscription and they also posted a rapidgator link.
People can also use softwares to detect and remove duplicate files easily so no need for much extra work or just sort by dates to pick until his last upload.
Not including old ones would be a pain for new people who would have to track down old posts and hope the links are alive and would probably be hard for the software they use to sort all that to know what is actually new.
People can also use softwares to detect and remove duplicate files easily so no need for much extra work or just sort by dates to pick until his last upload.
Not including old ones would be a pain for new people who would have to track down old posts and hope the links are alive and would probably be hard for the software they use to sort all that to know what is actually new.
I wouldn't know how to make that monofile with ffmpeg. I use Audacity to merge channels and encode as variable bitrate ogg for now. Better than mp3 in retaining information at the same bitrates. I use the webbased Whisper only. If I were to try and upload uncompressed files, I'd have to wait forever for them to be uploaded and I'd get messages about being inactive and get logged off. Upload to Whisper is pretty slow.Have you tried making a mono file in the same way whisper does, with ffmpeg, to test it? Maybe whatever you're using is not using the same process and creating a different result or if you skip also making it 16k and leaving it at the original, it influence things.
Just curious because it makes no sense that it would be any different unless the resulting audio is altered in some way.
Edit: With the above, I assumed you used wav when making them mono but if that's not the case, then that's likely the problem right there, you're doing an extra lossy encoding pass so you're losing details more than if you didn't do anything.
Also, I tried Whisper with an ac3 file once but that didn't work. It couldn't convert that to wav.
I could try flac, since that's not re-encoding the audio, but the files will still be very big.
So, if I want to use the Command prompt or powershell to encode audio to mono with ffmpeg, what do I do?
Do I use your example:
Open powershell in the directory for ffmpeg:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wav ?
Change input.mp3 to input.wav.
Will that work?
Done:
ffmpeg -i input.wav -ar 16000 -ac 1 -c:a pcm_s16le output.wav
I got a 250MB file from a 1.18GB file. Is that correct? It's been downsampled a lot, right?
Will this work better than a mono file from Audacity?
I'll try it, anyway.
Attachments
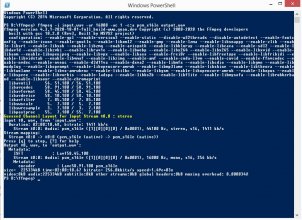
Assuming that you're outputting wav(or some other lossless format but you used wav for the ffmpeg input so must be wav) from audacity after doing whatever processing you wanted, that's the right command to use, it's what whisper does anyway.
And yeah, you'll get a fairly small wav file, around 250 Kbps if I remember right(exactly 256 from your screenshot), at most twice what youd get with usual default settings from other formats. The result should be the same as uploading the original audio but with the processing you did to it, without the extra lossy encode you did to ogg(likely opus) before.
If you still get a worse result that way, I'll be very confused, assuming you do output to lossless from audacity.
I never tried ac3 but it should work with ffmpeg, I did a dts file successfully once and I'm almost certain ffmpeg supports ac3 so must be something else that interfered that time.
And yeah, you'll get a fairly small wav file, around 250 Kbps if I remember right(exactly 256 from your screenshot), at most twice what youd get with usual default settings from other formats. The result should be the same as uploading the original audio but with the processing you did to it, without the extra lossy encode you did to ogg(likely opus) before.
If you still get a worse result that way, I'll be very confused, assuming you do output to lossless from audacity.
I never tried ac3 but it should work with ffmpeg, I did a dts file successfully once and I'm almost certain ffmpeg supports ac3 so must be something else that interfered that time.

So that ffmpeg command you listed is the one they recommend:I wouldn't know how to make that monofile with ffmpeg. I use Audacity to merge channels and encode as variable bitrate ogg for now. Better than mp3 in retaining information at the same bitrates. I use the webbased Whisper only. If I were to try and upload uncompressed files, I'd have to wait forever for them to be uploaded and I'd get messages about being inactive and get logged off. Upload to Whisper is pretty slow.
Also, I tried Whisper with an ac3 file once but that didn't work. It couldn't convert that to wav.
I could try flac, since that's not re-encoding the audio, but the files will still be very big.
So, if I want to use the Command prompt or powershell to encode audio to mono with ffmpeg, what do I do?
Do I use your example:
Open powershell in the directory for ffmpeg:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wav ?
Change input.mp3 to input.wav.
Will that work?
Done:
ffmpeg -i input.wav -ar 16000 -ac 1 -c:a pcm_s16le output.wav
I got a 250MB file from a 1.18GB file. Is that correct? It's been downsampled a lot, right?
Will this work better than a mono file from Audacity?
I'll try it, anyway.
On a bash shell I just loop through and convert all my mp4s to wavs:
for f in *.mp4; do ffmpeg -n -i "$f" -ar 16000 -ac 1 -c:a pcm_s16le "../wav/${f%.mp4}.wav"; done
I've also noticed sometimes some models work better than others, so if a movie is proving difficult I'll run a couple different models and then merge the results and clean up in aegisub.
I just pull models from here: https://huggingface.co/models?language=ja&other=whisper
Also sometimes it helps if you use an offset, so if the dialogue doesnt start for a while the transcription can be poor, so if you know the dialogue starts at 3 minutes in, then trim that off the beginning of the file, and then just offset the SRT post-processing. At least for whisper.cpp there is a parameter to do offset that makes things easier.
Last edited:
So, if I use the web version of Whisper, how can I use different models?
https://colab.research.google.com/g...in/WhisperWithVAD.ipynb#scrollTo=jh24lirNZnXT
Unless someone makes a version of Whisper as a simple installation exe with a Windows GUI, I won't be installing it. Also, on this computer I don't have a graphics card with lots of memory that I can use. It would probably take forever if what people in this thread are saying is true.
https://colab.research.google.com/g...in/WhisperWithVAD.ipynb#scrollTo=jh24lirNZnXT
Unless someone makes a version of Whisper as a simple installation exe with a Windows GUI, I won't be installing it. Also, on this computer I don't have a graphics card with lots of memory that I can use. It would probably take forever if what people in this thread are saying is true.
Here's a Windows port: https://github.com/Const-me/WhisperUnless someone makes a version of Whisper as a simple installation exe with a Windows GUI, I won't be installing it. Also, on this computer I don't have a graphics card with lots of memory that I can use. It would probably take forever if what people in this thread are saying is true.
So how do I actually download models from HuggingFace? The links lead to pages with lots of info on the models and there's a file section but there's no .bin to download like there is here: https://huggingface.co/datasets/ggerganov/whisper.cpp/tree/mainSo that ffmpeg command you listed is the one they recommend:
On a bash shell I just loop through and convert all my mp4s to wavs:
for f in *.mp4; do ffmpeg -n -i "$f" -ar 16000 -ac 1 -c:a pcm_s16le "../wav/${f%.mp4}.wav"; done
I've also noticed sometimes some models work better than others, so if a movie is proving difficult I'll run a couple different models and then merge the results and clean up in aegisub.
I just pull models from here: https://huggingface.co/models?language=ja&other=whisper
Also sometimes it helps if you use an offset, so if the dialogue doesnt start for a while the transcription can be poor, so if you know the dialogue starts at 3 minutes in, then trim that off the beginning of the file, and then just offset the SRT post-processing. At least for whisper.cpp there is a parameter to do offset that makes things easier.
For example: https://huggingface.co/openai/whisper-large-v2/tree/main
15 files and three of them are 6.17GB. None are bin files.
I got pointed to the WhisperDesktop program so I'm trying to find as many options for that as possible.
Thanks.
so if you don't want to use the command line and are using a colab network you can add a few lines of code to pull the model. they are very large though...So how do I actually download models from HuggingFace? The links lead to pages with lots of info on the models and there's a file section but there's no .bin to download like there is here: https://huggingface.co/datasets/ggerganov/whisper.cpp/tree/main
For example: https://huggingface.co/openai/whisper-large-v2/tree/main
15 files and three of them are 6.17GB. None are bin files.
I got pointed to the WhisperDesktop program so I'm trying to find as many options for that as possible.
Thanks.

Downloading models
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
from huggingface_hub import hf_hub_url, cached_download
import joblib
REPO_ID = "YOUR_REPO_ID"
FILENAME = "sklearn_model.joblib"
model = joblib.load(cached_download(
hf_hub_url(REPO_ID, FILENAME)
))
Using the WhisperDesktop and the medium.bin from the link, I get a very large srt but with mostly music notes and one or two different lines of the same subtitle repeated ad nauseam. Maybe 20-30 lines of proper dialog in all.
I'm trying with the large file now. If that doesn't work, I'll just have to go on with the web version.
I'm trying with the large file now. If that doesn't work, I'll just have to go on with the web version.
When evaluating models don't worry about looking at the output from several models over a 2 hr movie. Sometimes I'll get repeating lines or music as you said, so I will have to add an offset. If using whisper.cpp you can add an offset using the '-ot' parameter. It's in milliseconds. So if dialogue doesnt start until 1min 30 sec, i'll add '-ot 90000' . Sometimes whisper also sorta drops out due to how it's looking at previous tokens, so if i notice dialogue failing later on i'll just rerun those portions but only for 20-40 minutes or whatever I need for decent coverage.Using the WhisperDesktop and the medium.bin from the link, I get a very large srt but with mostly music notes and one or two different lines of the same subtitle repeated ad nauseam. Maybe 20-30 lines of proper dialog in all.
I'm trying with the large file now. If that doesn't work, I'll just have to go on with the web version.
example for starting 60 minutes into a movie to grab the last half of it:
main -m models/ggml-medium-ja.bin -f "VAGU-252.wav" -ot 3600000 -d 3657000-l ja -otxt -osrt -ocsv -of VAGU-252_1hr.ja-whisper-medium
I don't see VAD (Voice Activity Detection) in that version. It was a hassle to install https://colab.research.google.com/github/ANonEntity/WhisperWithVAD/blob/main/WhisperWithVAD.ipynb locally but it was worth it. There were so many things to install like CUDA, cudnn, (I think these two are already installed if you have used javplayer before), install https://pytorch.org, andUsing the WhisperDesktop
repeated ad nauseam. Maybe 20-30 lines of proper dialog in all.
Python:
pip install deepl srt ffmpeg-python
pip install git+https://github.com/openai/whisper.gitI have Python 3.9.13 and no compatibility issues. I can't say if Python 3.10 and newer have issues or not with packages like numpy, numba, etc. On my local pc, I changed the code so that it can queue up multiple audio paths. I can leave my pc on when I'm not home and whisper moves on to the next file. https://drive.google.com/file/d/1z1YX-YVgTZ2LoGDxmcK3BSYnZrWpSLYg/view?usp=share_link. I will explain the changes. Global variables for all the vad settings except audio_path is a parameter. Made a function called use_whisper and indented all the previous code into it. To queue up multiple audio, just copy paste use_whisper("your_path_to_audio_file") at the end (There is commented out code as an example). Also I added more words to the garbage list. Sounds like crackling and crying, and hallucinations such as, It's in my belly, and thank you for dinner gets deleted. To run, type python whisper-vad-function.py

VENU-156 Miki Sato Copulation Steam Bath Incest Mother And Child

I used Whisper to produce this subtitle file for Venu156. I love this actress and I wanted to sub this movie because it seemed to have the same actor as the mother-son couple in Venu-348. My objective was to make it a prequel to VENU-348. As always however, I still had to clean it up a bit and re-interpreted some of the meaningless/ "lewd-less" dialog. Again, I don't understand Japanese or Chinese so my re-interpretations might not be totally accurate but I try to match what is happening in the scene. Anyway, enjoy and let me know what you think of my "prequel".
Attachments

I used Whisper to produce three more subtitle files for Venu-109, Venu-144, and Venu-169; which all stared Miki Satou. As always, I had to clean them up a bit and re-interpreted some of the meaningless/ "lewd-less" dialog. Again, I don't understand Japanese or Chinese so my re-interpretations might not be totally accurate but I try to match what is happening in the scene. Anyway, enjoy and let me know what you think..
Attachments
FERA-118 I Started Living On My Own And My Mom Helped Me Move Into My New Apartment. After Hearing The Screams Of Sexual Pleasure Cumming From My Next Door Neighbor, She Got So Horny She Jumped On Me. Reiko Sawamura

I used Whisper to produce this subtitle file for FERA-118. I still had to clean it up a bit and re-interpreted some of the meaningless/ "lewd-less" dialog. Again, I don't understand Japanese or Chinese so my re-interpretations might not be totally accurate but I try to match what is happening in the scene. Anyway, enjoy and let me know what you think.
Attachments
My favorite genre is incest, and I really was curious about those reality type vids where they pick up family members off the street and interview them first before leaving them alone in a room to have sex. Unfortunately those types of vids don't get translated much, probably because those have a lot of "pointless" dialogue. But I think the dialogue adds a lot to the background of the characters and the dynamics of their relationships. So I went primarily for those when playing around with Whisper and uh... the results weren't super great. Even playing around with vad and chunk thresholds still made for extremely messy translations. But at least I can get the gist of the conversations now.
I also tried some dramatic movies and Whisper works so much better for those. It still has a lot of mistakes throughout, but the first attempt is usually satisfactory for me, unlike with reality vids where I have to do multiple attempts and have to piece shit together or figure out the context myself.
Here's three completely unedited drama subtitles (DLDSS-030, DASD-862, SPRD-678) that I put through Whisper on default settings. I haven't even watched through them, but skimming through the lines they seem okay.



I also tried some dramatic movies and Whisper works so much better for those. It still has a lot of mistakes throughout, but the first attempt is usually satisfactory for me, unlike with reality vids where I have to do multiple attempts and have to piece shit together or figure out the context myself.
Here's three completely unedited drama subtitles (DLDSS-030, DASD-862, SPRD-678) that I put through Whisper on default settings. I haven't even watched through them, but skimming through the lines they seem okay.
Attachments
FERA-25 Love Lust Sex Ryoko Murakami Excess Sabishinbo Mother.

I used Whisper to produce this subtitle file for FERA-025. You gotta love Ryoko's huge boobs! I still had to clean it up a bit and re-interpreted some of the meaningless/ "lewd-less" dialog. Again, I don't understand Japanese or Chinese so my re-interpretations might not be totally accurate but I try to match what is happening in the scene. Anyway, enjoy and let me know what you think.
Attachments
You could have saved yourself some time friend, both of those been sub for years. I think 3-4 month ago I was watching them both.VENU-156 Miki Sato Copulation Steam Bath Incest Mother And Child
I used Whisper to produce this subtitle file for Venu156. I love this actress and I wanted to sub this movie because it seemed to have the same actor as the mother-son couple in Venu-348. My objective was to make it a prequel to VENU-348. As always however, I still had to clean it up a bit and re-interpreted some of the meaningless/ "lewd-less" dialog. Again, I don't understand Japanese or Chinese so my re-interpretations might not be totally accurate but I try to match what is happening in the scene. Anyway, enjoy and let me know what you think of my "prequel".
Didn't care too much for Venu-348 like I last remember, the son was just too willing to get caught.
But I always appreciate your effort. Your version could be better
