


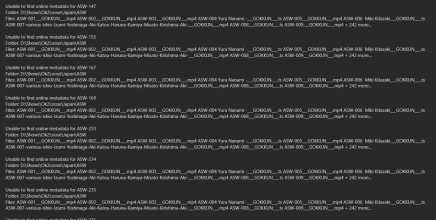
It seems to be a little more obscure titles it misses although Ive manually checked the scrapers and the info is present. As you said, must be a counter measure to avoid scraping maybe.Are you getting A message after scanning saying "This file exists somewhere else in Your collection"?
Im also sure theres a setting you can toggle to make covers or .nfo for movies it finds no Info on. TmpGuy will help you better ofc
Here it is under settings.
View attachment 3487273
If you are a new user then a tip I employ when batch adding a lot of movies but I am unsure whats new and whats not in JAVLUV especially as the NEW [Toggle] doesnt always function the best if release dates are missing and so on. Anyway, I have a folder I dump ALL new downloads into and Call it say NEW-JAV-DOWNLOADS
Now dump all your new jav in there and scan it with Javluv. Now in the search box in JavLuv, Copy and paste the folder name: NEW-JAV-DOWNLOADS and only movies within that folder will be displayed which makes it a thousand times easier if you are a serial hoarder like me. NOTE: You can do this with any folder. Call it a series name, content name like [Massage] or [NAMPA] and only folders, filenames with that wording will be shown.
If you are doing as I stated before though, for a SORTING folder then give it a Unique name and not NAMPA lol and keep it one word like NEWDOWNLOADS2024 or If you say call it NEW-NAMPA-DOWNLOADS then all NAMPA words, All Download words and all NEW words will be flagged but keep it one word and only that entire folder will be displayed if that makes sense. Just smoked a large one lol so........................
EDIT: @TmpGuy Ive done several others now that have failed miserably and the info is there as Ive manually checked. It seems hit and miss atm.
Last edited by a moderator:


")